Learn to Build RAG Application using AWS Bedrock and LangChain

Welcome to the exciting world of natural language processing and machine learning! In this article, we’ll dive deep into the Retrieval-Augmented Generation (RAG) concept and explore how it can be used to enhance the capabilities of language models. We will also build a cool end-to-end application using these concepts.
But before deep diving into the application, let’s understand what RAG is, its use cases, and its benefits.
Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model so it references an authoritative knowledge base outside of its training data sources before generating a response.
In short, Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources. In other words, it fills a gap in how LLMs work.
The two main benefits are that it ensures that the model has access to the most current, reliable facts and that users have access to its sources, ensuring that its claims can be checked for accuracy and ultimately trusted.
With retrieval-augmented generation, users can have conversations with their data repositories. For example, a generative AI model supplemented with a medical index could be a great assistant for a doctor or nurse. Customer support chatbots with access to guides and the latest product manuals can provide more accurate and contextually appropriate responses.
In this article, I will explain how to create a simple RAG application to query your own PDFs step by step. For this task, we will leverage Mistral’s latest model, “Large”, using AWS Bedrock and LangChain framework.
Let’s get the learning started. The implementation of this application involves three components:
1. Create a Vector Store
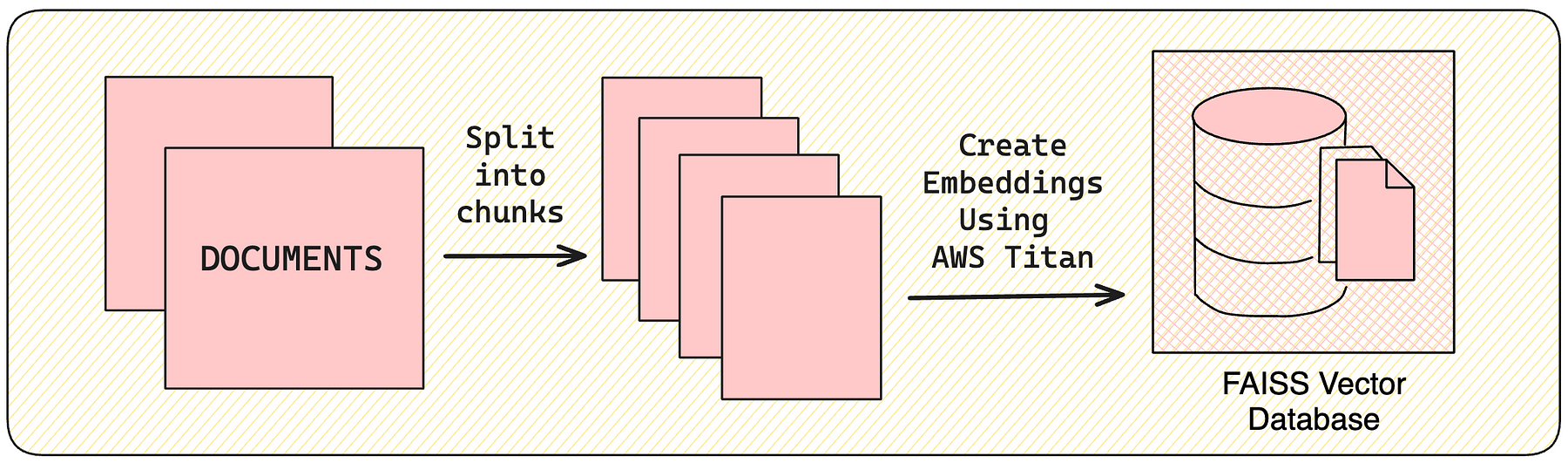
- Load -> Transform -> Embed.
We will be using the FAISS vector database, which uses the Facebook AI Similarity Search (FAISS) library. There are many excellent vector store options that you can use, such as ChromaDB or LanceDB.
2. Query Vector Store and ‘Retrieve Most Similar.’

The way to handle this is at query time, embed the unstructured query and retrieve the embedding vectors that are ‘most similar’ to the embedded query. A vector store takes care of storing embedded data and performing vector search for you.
3. Frame the response using LLM and ‘Enhanced Context’
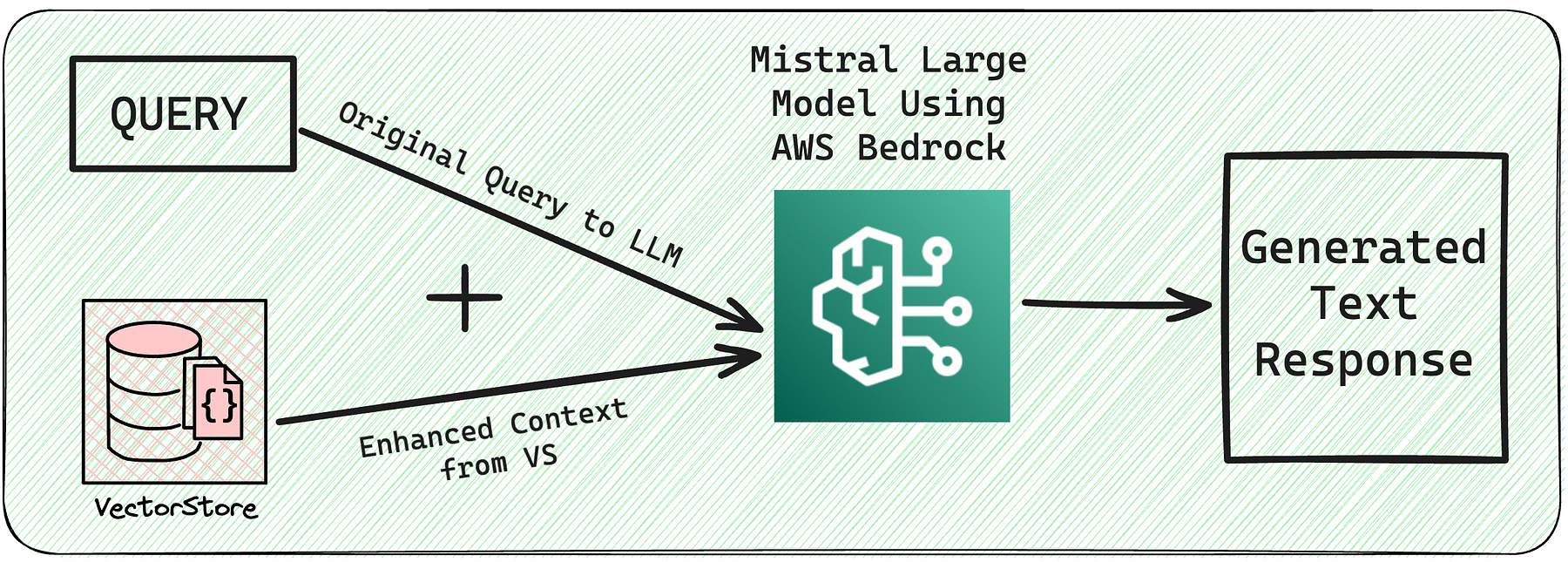
Response Generation Using LLM (Large Language Model): Once the relevant documents are retrieved from Vector Store, a large language model uses the information from these documents to generate a coherent and contextually appropriate response.
These three steps clearly explain the application we are going to build now.
First and foremost, we will set up our AWS SDK for Python using Boto3 and AWS CLI. If you have not installed them before —
(base) ➜ ~ pip3 install boto3
(base) ➜ ~ pip3 install awscli
(base) ➜ ~ aws configure
In this example, we’ll use the AWS Titan Embeddings model to generate embeddings. You can use any model that generates embeddings.
import boto3
# Load the Bedrock client using Boto3.
bedrock = boto3.client(service_name='bedrock-runtime')
from langchain_community.embeddings.bedrock import BedrockEmbeddings
titan_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1",
client=bedrock)
Now, we will set up the Vector Store to store and retrieve embeddings. We have our PDF stored in the “data” folder of the root directory.
-
In this case we’ll split our documents into chunks of 1000 characters with 200 characters of overlap between chunks. The overlap helps mitigate the possibility of separating a statement from an important context related to it.
-
We will leverage RecursiveCharacterTextSplitter from LangChain, which will recursively split the document using common separators like new lines until each chunk is the appropriate size.
-
We can embed and store all of our document splits in a single command using the FAISS vector store and titan embedding model.
# Vector Store for Vector Embeddings
from langchain_community.vectorstores.faiss import FAISS
# Imports for Data Ingestion
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders.pdf import PyPDFDirectoryLoader
# Load the PDFs from the directory
def data_ingestion():
loader = PyPDFDirectoryLoader("data")
documents = loader.load()
# Split the text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=200)
docs = text_splitter.split_documents(documents)
return docs
# Vector Store for Vector Embeddings
def setup_vector_store(documents):
# Create a vector store using the documents and the embeddings
vector_store = FAISS.from_documents(
documents,
titan_embeddings,
)
# Save the vector store locally
vector_store.save_local("faiss_index")
The next step is to import and load the LLM via Bedrock.
# Import Bedrock for LLM
from langchain_community.llms.bedrock import Bedrock
# Load the LLM from the Bedrock
def load_llm():
llm = Bedrock(model_id="mistral.mistral-large-2402-v1:0",
client=bedrock, model_kwargs={"max_tokens": 512})
return llm
We will be using LangChain PromptTemplate to create the prompt template for our LLM. We will produce an answer using a prompt that includes the question and the retrieved data (context).
from langchain.prompts import PromptTemplate
# Create a prompt template
prompt_template = """Use the following pieces of context to answer the
question at the end. Please follow the following rules:
1. If the answer is not within the context knowledge, kindly state
that you do not know, rather than attempting to fabricate a response.
2. If you find the answer, please craft a detailed and concise response
to the question at the end. Aim for a summary of max 250 words, ensuring
that your explanation is thorough.
{context}
Question: {question}
Helpful Answer:"""
PROMPT = PromptTemplate(template=prompt_template,
input_variables=["context", "question"])
Now, let’s write the actual application logic. We want to create a simple application that takes a user question, searches for documents relevant to that question, passes the retrieved documents and initial question to a model, and returns an answer.
We need to define the LangChain Retriever interface. Load RetrievalQA from LangChain as it provides a simple interface for interacting with the LLM.
from langchain.chains.retrieval_qa.base import RetrievalQA
# Create a RetrievalQA chain and invoke the LLM
def get_response(llm, vector_store, query):
retrieval_qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vector_store.as_retriever(
search_type="similarity", search_kwargs={"k": 3}
),
chain_type_kwargs={"prompt": PROMPT},
return_source_documents=True,
)
return retrieval_qa
Let’s put it all together into a chain. This tutorial will use Streamlit to create a UI that interacts with our RAG.
-
We will provide a simple button in the sidebar to create and update a vector store and store it in the local storage.
-
Whenever a user enters a query, we will first get the faiss_index from our local storage and then query our LLM using the retrieved context.
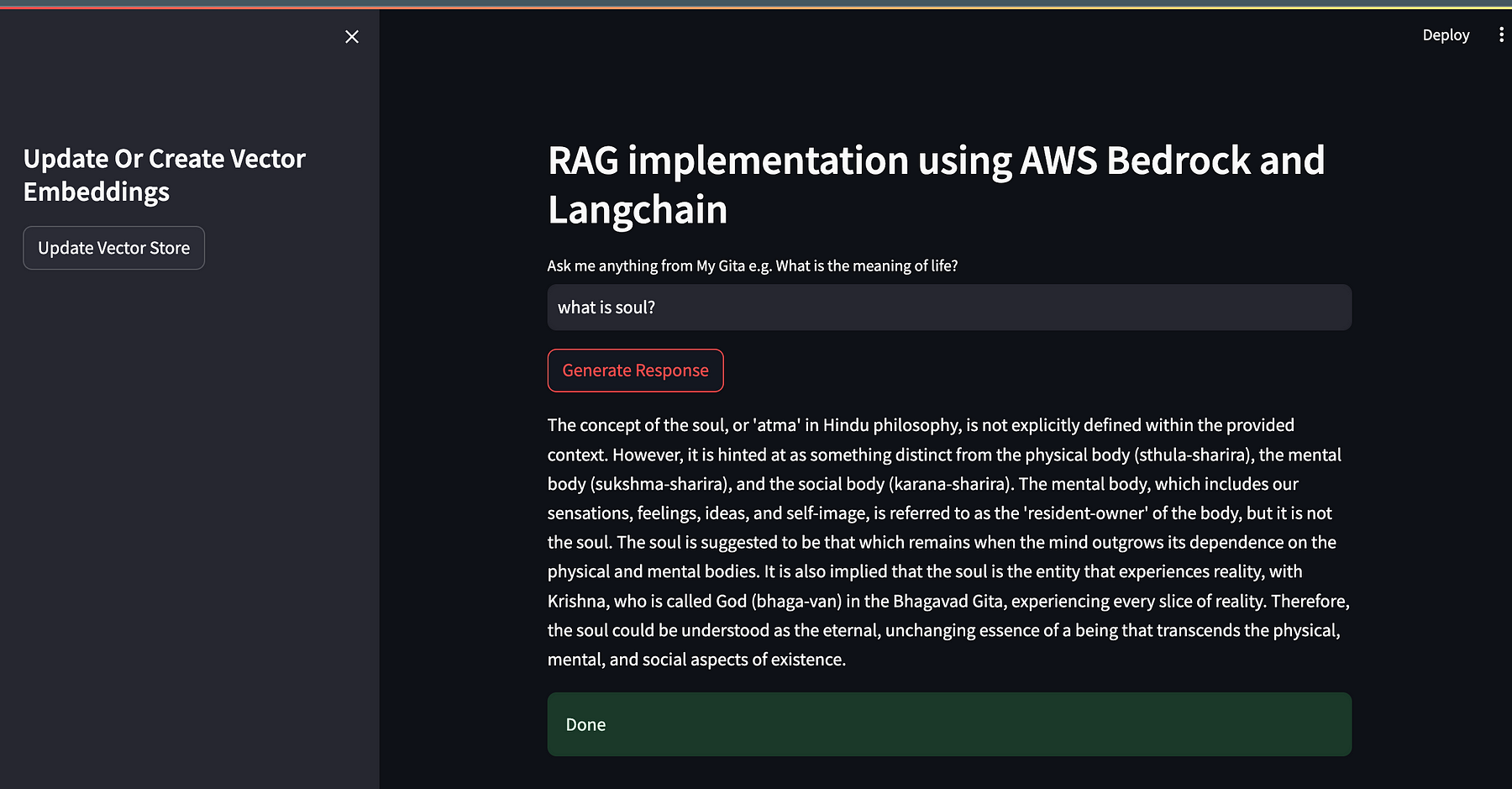
def streamlit_ui():
st.set_page_config("My Gita RAG")
st.header("RAG implementation using AWS Bedrock and Langchain")
user_question = st.text_input("Ask me anything from My Gita e.g.
What is the meaning of life?")
with st.sidebar:
st.title("Update Or Create Vector Embeddings")
if st.button("Update Vector Store"):
with st.spinner("Processing..."):
docs = data_ingestion()
setup_vector_store(docs)
st.success("Done")
if st.button("Generate Response") or user_question:
# first check if the vector store exists
if not os.path.exists("faiss_index"):
st.error("Please create the vector store
first from the sidebar.")
return
if not user_question:
st.error("Please enter a question.")
return
with st.spinner("Processing..."):
faiss_index = FAISS.load_local("faiss_index",
embeddings=titan_embeddings,
allow_dangerous_deserialization=True)
llm = load_llm()
st.write(get_response(llm, faiss_index, user_question))
st.success("Done")
This is how our Streamlit application will look.
The complete code for the application is available here on my github: somilg050.

You can play around with the code by customizing the prompt and changing the parameters to the LLM.
Recap
This article taught us about RAG, the benefits of building RAG applications, and how people leverage this concept. Then, we built an application using this concept with the potential of RAG to provide contextually relevant and cited responses and open up new possibilities for developers to innovate and explore.
Moreover, the success of startups like Fintool, which utilize RAG to create innovative products, further highlights the impact and versatility of this technology.
As we continue to push the boundaries of what’s possible with LLMs, integrating Retrieval and Generation techniques, undoubtedly plays a crucial role in knowledge discovery.
Thanks for reading the tutorial. I hope you learn something new today. If you want to read more stories like this, I invite you to follow me.
Till then, Sayonara! I wish you the best in your learning journey.
I am a software engineer who enjoys travelling and writing — About Me.
© Somil Gupta.Made with ♥ in India.